
识别拼图网络
识别是否为类似以下图片,有性能要求

魔改的经典cnn识别mnist模型
准确率能上94%,但项目要求准确率比较高,至少99,在考虑其他传统方案
尝试了[2201.03545] A ConvNet for the 2020s,准确度确实能提升一点,但项目也要求性能。
mask rcnn识别
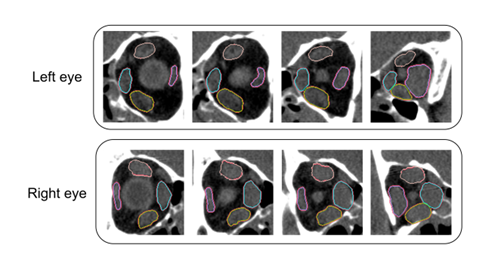
打算用mask-rcnn做一个MRI的眼眶识别,识别肌肉等组织。做完了前期工作,转换为了coco标准的json,参考GitHub - brunobelloni/binary-to-coco-json-converter: Convert segmentation binary mask images to COCO JSON format.
同样的想法被做了,效果还很好,按道理ct应该比mri难做
Deep Learning-Based Diagnosis of Disease Activity in Patients with Graves’ Orbitopathy Using Orbital SPECT/CT
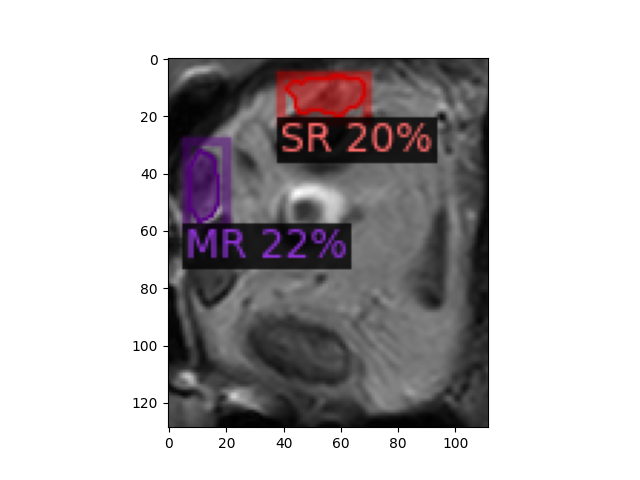
后记:mask rcnn可能收敛速度太慢了,感觉一直都不收敛。用原模型fine-tuning和重新训练效果都差不多。可能模型太深overfit了,精度和准确度一直上不去
U-Net
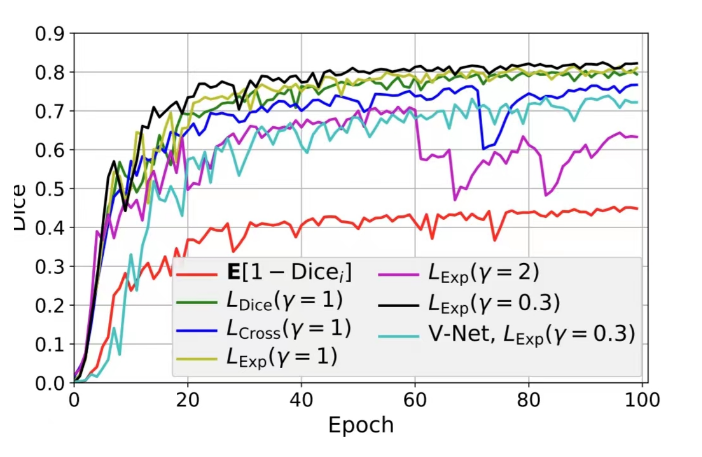
由于医学图像语义低,医学一直是u-net占据了主要地位,复现了GitHub - milesial/Pytorch-UNet: PyTorch implementation of the U-Net for image semantic segmentation with high quality images,魔改了下loss函数,效果大幅提升。看训练结果感觉有的比数据集标注的还好,训练最终稳定在dice=0.8。后期可以尝试nnUNet,模型和UNet没有区别,但是在数据增强,预处理上花了很多功夫。
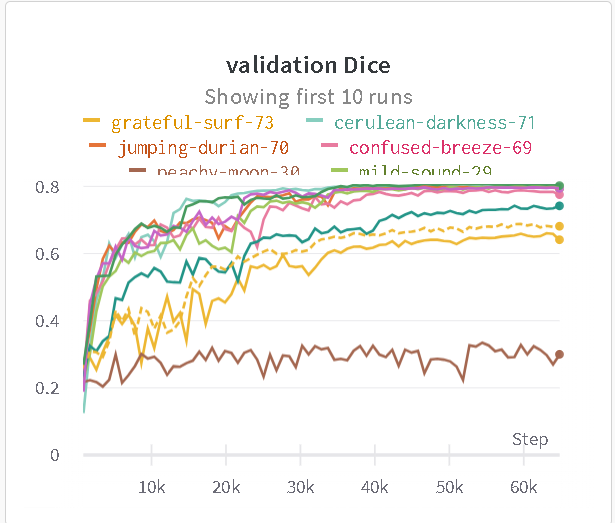
上图是我结合了很多种loss进行训练的结果,loss为explog的时候效果特别好,论文是[1809.00076] 3D Segmentation with Exponential Logarithmic Loss for Highly Unbalanced Object Sizes。看标题就知道和我遇到的问题一样,Unbalanced Object Sizes,下图来自论文里
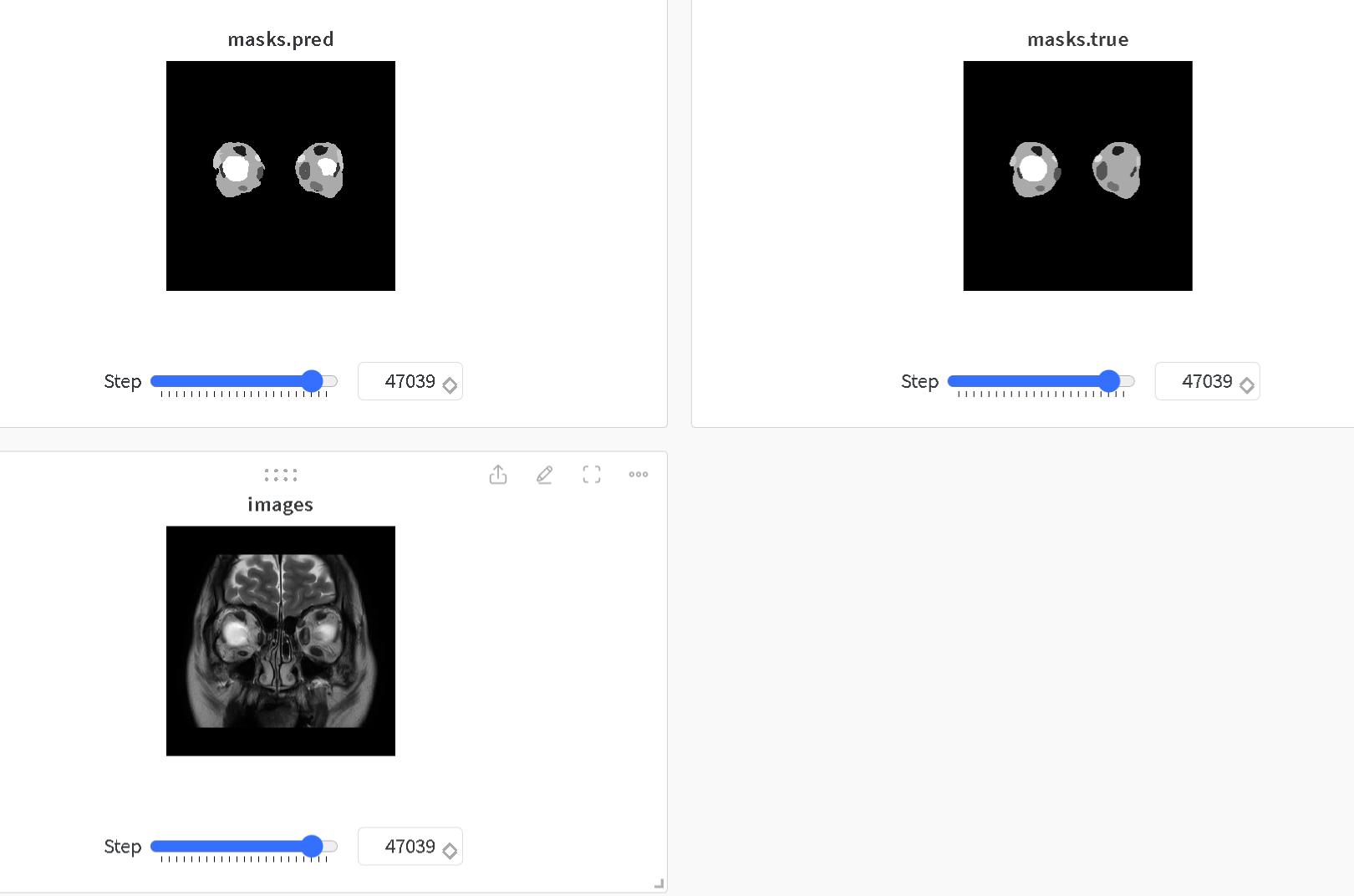
遇到了伪影的情况,标注的时候可能需要注意一下规范性,总的看起来效果还是不错的
关于loss的理论学习参考了【损失函数合集】超详细的语义分割中的Loss大盘点 - GiantPandaCV,文章写的很好,结合了很多论文的公式讲解。
RL学习
就复现了一下GitHub - Lazydok/RL-Pytorch-cartpole: Reinforcement Learning tutorial by pytorch,看了下Q函数等理论知识,等研究生要是有相关研究再细看吧

关于足球的RL还是挺有趣的,[1907.11180] Google Research Football: A Novel Reinforcement Learning Environment